上学期选修了数据仓库这门课
当时由于期末时间紧张还没有来得及记录一些东西
趁刚开学没啥事回顾一下
PS:本文着重于对于亚马逊电影数据的数据仓库构建过程,不详细描述数据仓库的相关概念。
数据仓库要求分析
款爷给了一个大型文本数据集合,大概八百万条电影评论数据,然后基于八百万条电影数据过滤出所有的电影ID,再根据这个电影ID去Amazon网站上爬取每一部电影的相关信息,分别存储在关系型数据库和分布式数据库,进行系统性能对比并且以数值和图表的方式展示。
文本数据集在此
http://snap.stanford.edu/data/web-Movies.html
数据仓库查询要求:
-
按照时间进行查询及统计(例如XX年有多少电影,XX年XX月有多少电影,XX年XX季度有多少电影,周二新增多少电影等)
-
按照电影名称进行查询及统计(例如 XX电影共有多少版本等)
-
按照导演进行查询及统计(例如 XX导演共有多少电影等)
-
按照演员进行查询及统计(例如 XX演员主演多少电影,XX演员参演多少电影等)
-
按照电影类别进行查询及统计(例如 Action电影共有多少,Adventure电影共有多少等)
-
按照上述条件的组合查询和统计
数据提取
-
前几次课程练习时使用的Pentaho公司的Kettle在这里派上了用处,用ETL工具对数据进行过滤并提取出电影ID,再拼接成类似
https://www.amazon.com/dp/B009V3CFPU的URL。 -
遍历生成的所有URL,使用Java爬取页面并对html进行信息提取,根据页面的样式筛选需要保存的内容,再插入到数据库中。强大的Java程序员@Novemser完成了这一部分。
这里要感谢嘉定区的电信,给我们寝室的路由器分配的是外网地址,而且每一次重启路由器都能分配到新的外网IP地址。
因为亚马逊做了一些反爬虫的措施,每当同一个IP爬取990个电影左右就会被屏蔽。所以@Novemser使用按键精灵定时重启路由器来更换IP,完美解决了这个问题。
一开始@Novemser打算用文本直接存储爬取的信息,但是这样之后不好处理,在爬虫挂掉的时候也没有办法找到挂掉的地方接着爬取,使用数据库存储就解决了。
数据清洗
建立数据仓库,需要先把表的结构建起来。
我们决定把每一部电影的数据作为事实表的一项,再把电影的派生信息包括上映时间、演员、导演等信息放到维度表中。
接下来,我们遇到的问题是,导演、主演演员以及参演演员等这些多对多的关系如何存储呢。
如果把每一部电影的所有演员以一个JSON数组的形式存储在电影事实表的一项中,就没有办法根据演员来查询了。
如果建立桥接表来桥接事实表和维度表,虽然可以满足多对多的关系,可是这样多表查询会对速度产生非常大的影响。
可以为了提高速度而做适当的冗余
款爷的这句话提点了我们,我们可以把所有演员以字符串的形式存储在电影的属性中,同时把某一个演员的演的所有电影以字符串的形式存储在演员维度表的属性中。虽然有比较多的冗余,但数据仓库就是作为这样一个为了查询速度而可以冗余的存在。
当表的结构决定好之后,就可以建表然后进行数据清洗了!
因为之前从网页上爬取的信息都是混在一起的裸JSON对象数据,需要按属性清洗到我们的表的对应的属性中去。这一项花了比较多的等待时间,因为数据量太大,使用ETL工具插入数据库速度太慢,我们决定还是使用Java来连接数据库直接插数据,大概花了一整天的时间才等机器插完数据进数据库。
分布式数据库
虽然课上介绍了Hadoop,然而手动搭建Hadoop环境需要花费的时间太漫长了。幸亏有@Novemser强大的主机支持,可以使用Cloudera集成的分布式虚拟机环境,可以采用Cloudera的Impala查询系统来完成我们的分布式数据库部分。
因为Hive每次查询都要开启MapReduce,时间太长,不适合这种实时查询的环境。而Impala借鉴了MPP并行数据库的思想,有更多的优化空间,
主要是把数据导入到HBase,Impala会利用HBase里面的元数据进行查询。
应用层和展示层
持久层的工作完成后,就是应用层和展示层了。
我们采用了前后端分离的方式,@Novemser使用了Spring框架完成了应用层,提供了API给前端调用。
而我使用React框架以及Material-UI和Recharts组件完成前端页面的构建以及前后端API的适配。
为了查询优化,在前台直接缓存(写死)了939个电影类别、1万多个导演名称、4万多个演员名称、1万多个电影名称(电影名称有25万而鄙电脑的内存不够nodejs爆炸了),以至于第一次打开加载会很慢。
根据时间查询
这个页面的API有6个!
-
根据年份
-
根据年份和周几
-
根据年份和季度
-
根据年份和季度和周几
-
根据年份和月份
-
根据年份和月份和周几
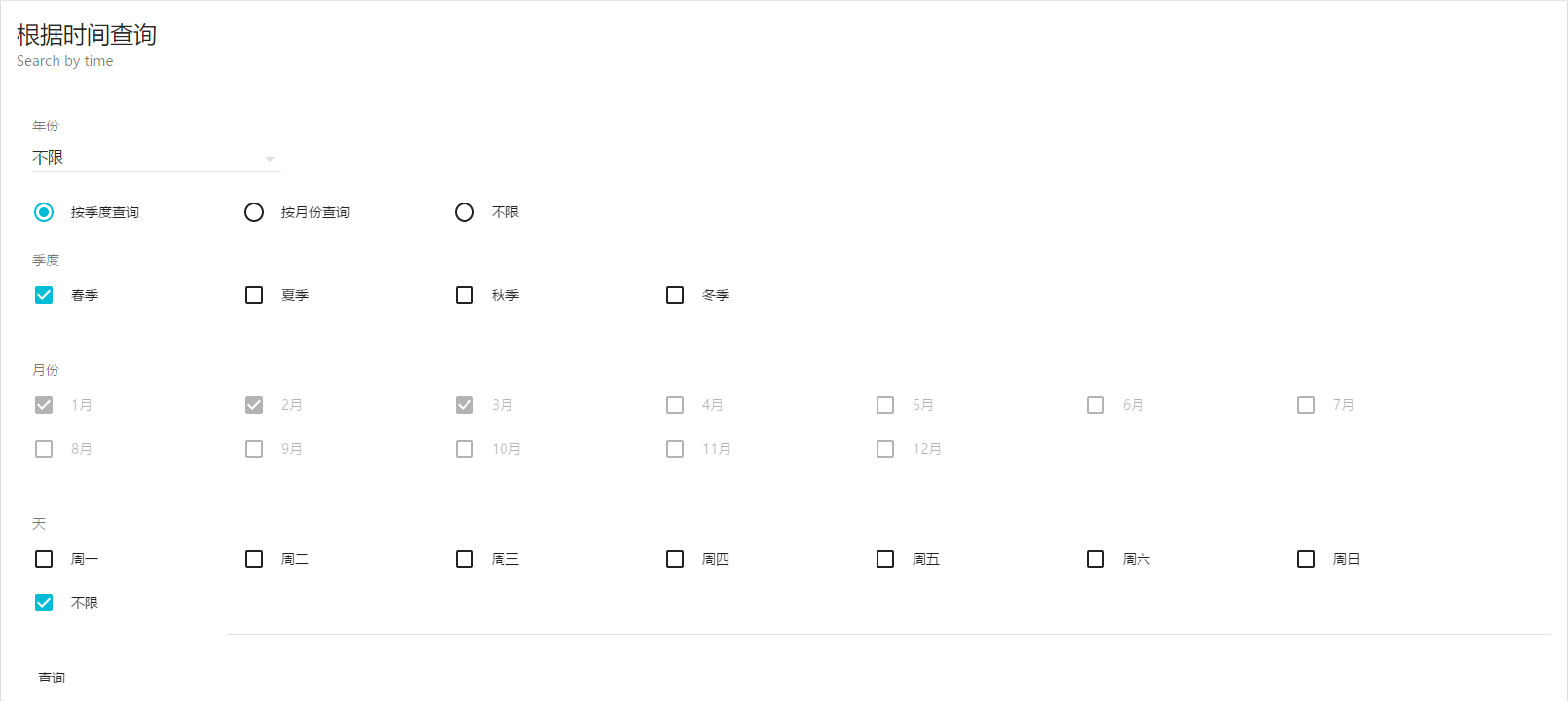
你们感受一下:)
好了到此结束。