接到一个朋友的请求去写一个爬虫
要求是给定一批公司的中文名称,比如"百胜(中国)投资有限公司"
到一个特定的网站(启|分割|信|分割|宝),抓取这个公司的对外投资的公司(子公司)的名称及其所属行业
登录
首先大概浏览了一下网站,发现其限制了未登录用户的搜索次数,于是我注册了个账户,然后在代码里模拟了登录的流程并且保存cookie。这里也没啥好讲的。
搜索
-
由于给定的是名称,那么要找到特定的公司页面就需要先搜索
-
伪造请求头
-
取第一个搜索结果,记下其链接
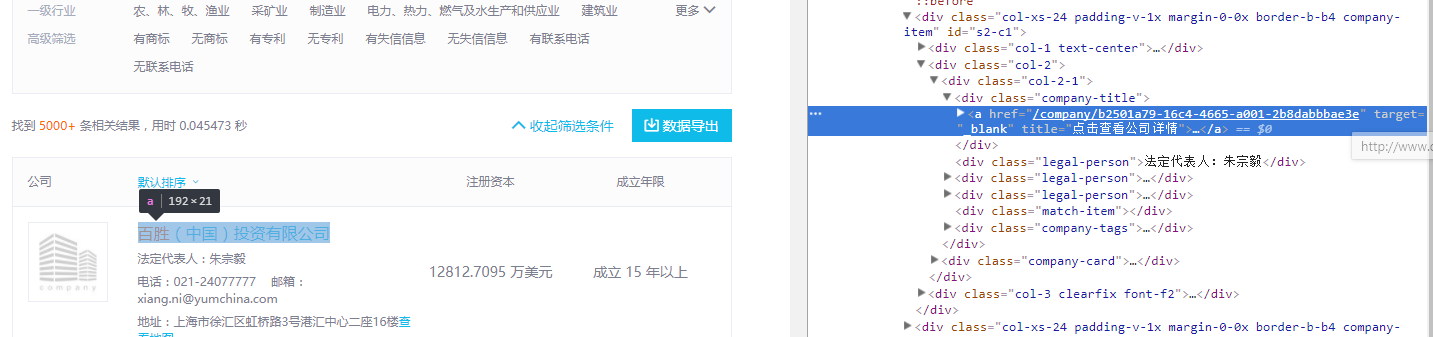
这里会发现,每一家企业都有一个特定36位长的字符串id,有了这个id就可以直接找到这家企业而无需搜索。然后我遇到了这个网站的第一个反爬虫措施
- 限制访问频率

所幸的是,我只要抓100家公司的资料,而这个网站是每当我抓20家公司就拦住我,因为懒所以我就抓20个就等一下再重开,5次之后完成了抓取公司的链接。
对外投资公司
进入到公司的主页之后,发现如果想要看对外投资公司的详情页,是有一个固定的URL,根据之前拿到的链接,做一下字符串操作就可以拿到对外投资公司详情页的链接。

进来页面之后,发现是分页的,会有翻页的按钮,这里主要是根据页面上一个标签显示的个数来判断
如果是0就不用抓。
否则看是否有页面分页按钮,如果不存在就只抓一页,存在就抓按钮的个数

正当我以为是按一页一页来解析html取结果的时候
我发现,翻页发出的请求,是Ajax请求!
POST数据是一串JSON,包括前面说的id和页码
{"eid":"b2501a79-16c4-4665-a001-2b8dabbbae3e","page":2}
而且连URL都是/api开头的哈哈哈哈心想这太方便了!

而这个接口返回的正好包括了我想要的结果!

那么,接下来就是for循环页数,每一页发一个请求,再把结果数组concat起来就好啦!
重头戏来了
我写好了URL
放好了cookie
模拟了请求头
写好了POST数据
结果爬的时候给我返回了
{"status": 500, "msg":"未知错误"}
??我???
你都告诉我有错了还故意不告诉我为什么???
然后我又重新仔细地看了一下请求头,看到了一串非常乱七八糟的字符串
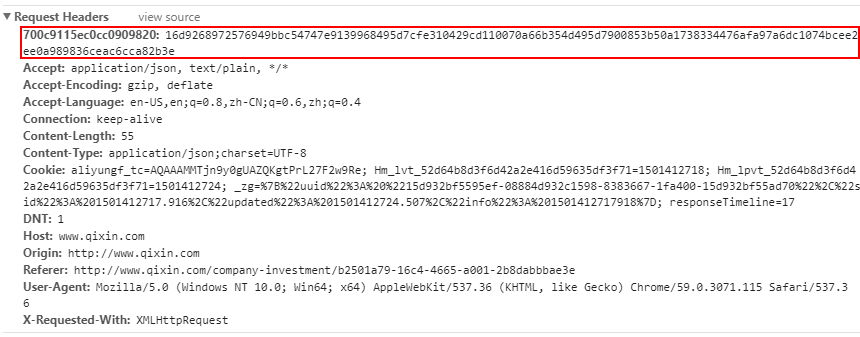
???这是什么鬼???
然后我发现,同一个URL的请求,这个key是长一样的,但是这个value长的不一样!!
value还是128位的!!!
我心想这一定是加密了的,我要怎么搞出来这128位的字符串啊!
不知所措的我,只好查看这个网页引用的js文件,发现用到了webpack打包,不仅被压缩了,还被混淆了!
- 用工具格式化了一下

混淆过的代码根本没法看好嘛!
于是我只好在chrome找到存储其请求URL的地方,打了一个断点
像这样
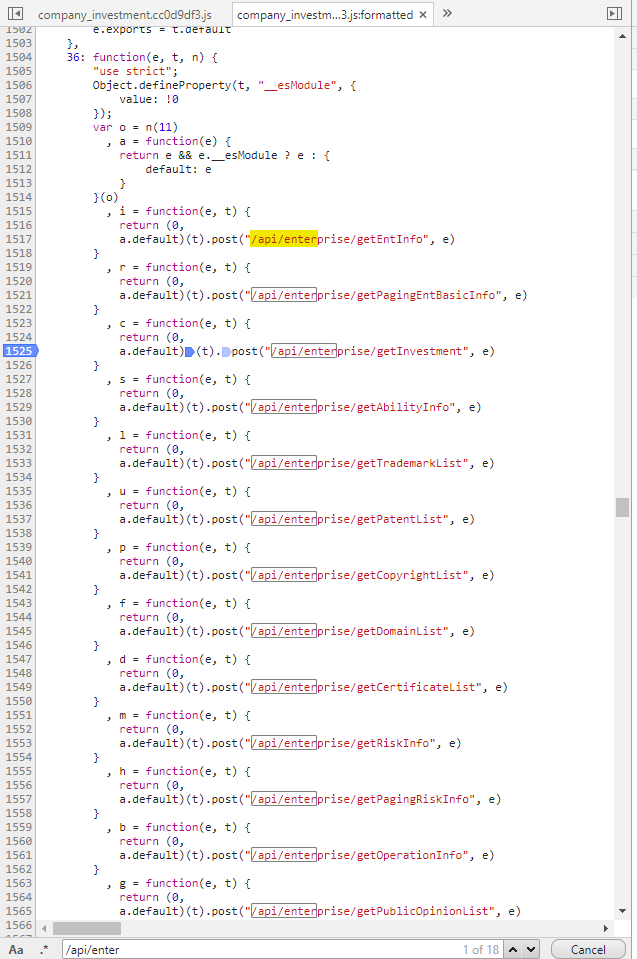
点击页面的按钮,到达断点,然后一步一步地按着F11,开始了怀疑人生的调试之旅。
在这个过程中,我一度想要放弃。。。。
幸运的是,我到达了这里,看到了SHA512和Hmac,我就知道了它用了什么加密算法:)
因为SHA512生成的hash值就是128位的!
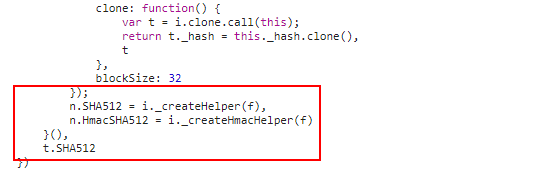
搜索了一下,发现这个算法需要一个秘钥
1 | 算法公式 : HMAC(K,M)=H(K⊕opad∣H(K⊕ipad∣M))[1] |
接下来,我只要知道它的秘钥是什么,以及它加密了什么内容,就完成了!!
同样非常高兴的是,我到达了这里,我就猜这个jG开头的58位字符串就是秘钥!

接下来,我来到了这里,看到它拼接了一段奇怪的字符串
是把请求的URL转成小写,然后重复两次,再拼上POST数据的JSON字符串
我猜,这就是要加密的明文吧!
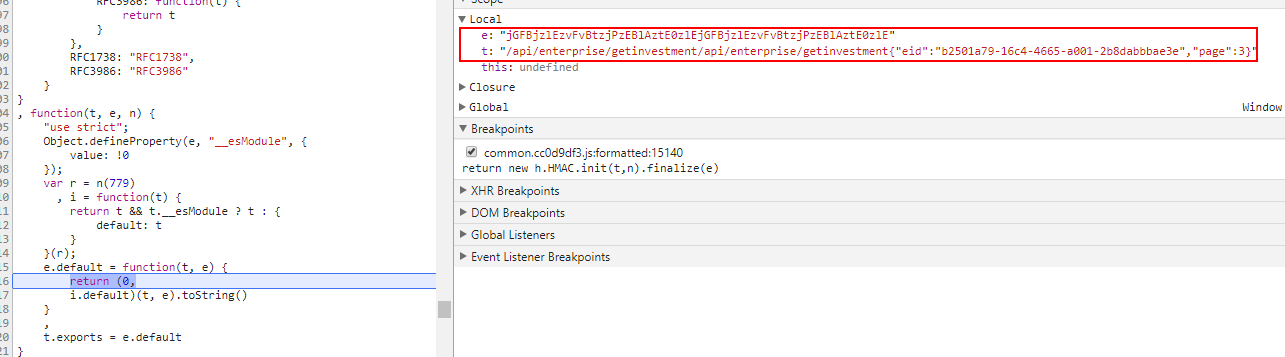
我就赶紧去试了一波~~

结果真的一模一样!!!乐开了花!!
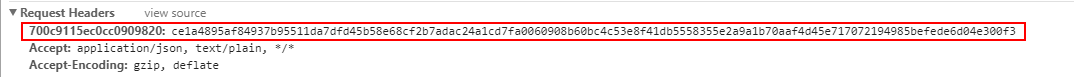
至于那个20位的key是怎么生成的我就没管了,但是可以确定是根据请求URL生成的
至此,这个操蛋的爬虫就算是写完了,接下来只是批量地跑就好了。
不得不感叹贵公司的前端还是很强啊!搞这么一个加密的请求头!折腾了我一个下午!
然后我去跟同学吹逼的时候发现,发现我同学居然就在这个公司实习,只是不在这个部门
他还说这个网站是个人用户免费,企业收好贵,主要就是免费用户没有导出的数据的功能
那我写的这个爬虫好像相当于在砸饭碗
顿时非常的害怕
7月要结束了
最近补完了旧番四月是你的谎言
好虐啊