说在前面
报错的监控和收集一直是各个互联网企业保证线上运作的产品稳定的措施。
先暂时笼统地把错误分为前端(本文仅讨论 Web 前端)和后端的报错。在大多数情况下,后端报错发生时,可以非常精确的定位到错误的发生位置,然后进行处理。
然而前端则不然,浏览器的种类繁多,各种兼容性问题层出不穷。同时还有因为用户网络问题才导致的错误,再者,还有全国各地运营商劫持 js 脚本同时造成报错的问题发生。 除此之外,还有一些只有在无头浏览器如 phantomjs 或者其它搜索引擎爬虫如 BingPreview 才会引发的报错。
以上种种情况,造成了前端报错数量不计其数,噪音数据多,又无法分辨错误是否与代码有关,导致难以处理。本文尝试从数据分析的角度,分析并过滤百姓网前端的报错,降低噪音数据,从中找到需要关注的错误。
数据来源
要进行数据分析,首先得拿到足够多的数据量。
百姓网使用 Sentry(一个开源的实时错误上报和监控工具)来收集前端的报错。由于数量庞大,目前只会存储最近15天的数据,笔者通过打 Sentry 的 API 的形式将 15 天的数据拉下来存储到本地 mongodb 数据库中,15 天算下来大概有 27000 个 event,1500 多个 issue 。
其中,每一个 issue 即一种错误,其和许多 event 构成了一种 一对多 的关系。
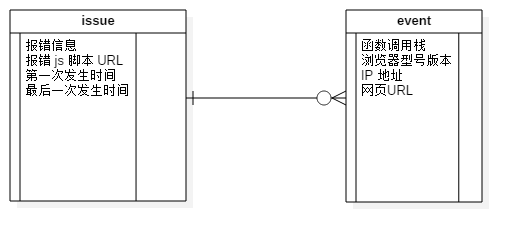
如图所示,Issue 本身记录了这种错误的报错信息、报错的 js 文件 url、第一次和最后一次发生时间等等信息,而 event 则存储了某一次发生的函数调用栈、浏览器型号版本、ip地址、网页 url 等等。这为我们进行数据分析提供了非常详尽的信息。
筛选方式
本文主要从三个角度进行报错信息的处理:
- 过滤劫持相关的报错
- 合并报错信息相似的 issue
- 筛选跟浏览器相关的报错
过滤劫持相关的报错
百姓网作为一个分类信息网站,用户遍布全国,但是全国的网络环境却不尽相同。事实上,有些地区运营商,会劫持一些流量大的网站的脚本,进而投放广告或用其他行为来获取利益。同时也可能造成一些正常情况下不会发生的报错。因此,第一个可以突破的点,就是过滤掉跟劫持相关的报错。
要过滤掉跟劫持相关的报错,首先是要判断出一个报错是否是跟劫持有关。鉴于劫持是地区运营商的行为,所以只要统计某个错误上报的各个地区的比例,如果某个地区占的比例特别大,就能很大程度上佐证这个错误是由于在这个地区被劫持而造成的,毕竟每个地区的代码是一样的。
正好,Sentry 存储的错误的上报数据中有 ip 地址,我们可以将 ip 地址转换为省份城市方式来统计错误地区比例。
其中 ip 到地址的转换有多种免费又不限制次数的方法,请大家自行摸索
这里有点奇怪的是,有一部分是来自美国、柬埔寨、越南、等十多个国外的地方。。。
转换结束后,首先统计了一下所有的 issue,按省份发生的次数排序 ↓
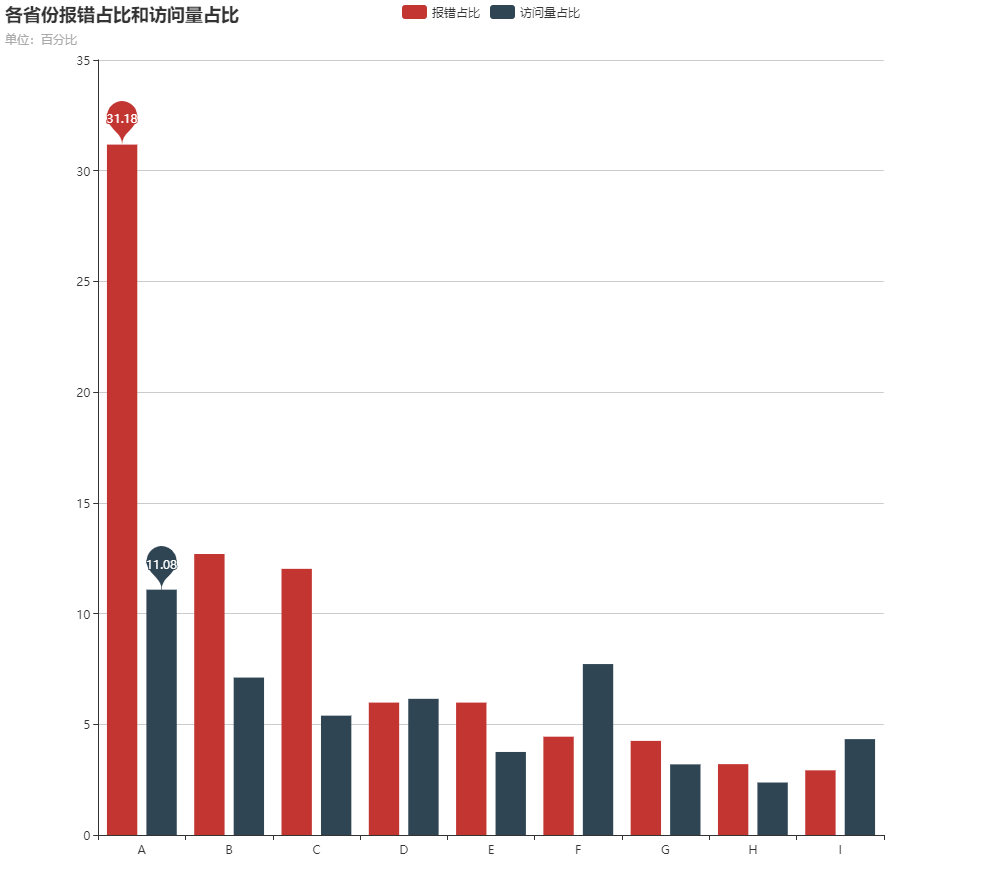
可以看出,A、B、C 这三个省份的占比特别大,而且省份 A 的报错占比居然比访问量占比大超过一倍。然而这三个省份的用户访问量并没有占到那么多。而往后的省份都比较低,根据其省份的用户访问量一起比较,差不多是在正常的水平。
根据这个情况,可以针对每一个 issue,统计该 issue 发生的所有 events 的地区,如果某一个地区占的比例非常大,那么这个 issue 很有可能是因为被运营商劫持而造成的。而且,统计出来占比较大的省份 A 和省份 B ,正是劫持情况最严重的的地区。这符合了我们最初的猜想。
于是,A, B, C 三个省份被我们列为"黑名单",把报错中这些地区占比较大的 issue 过滤掉,打算看看剩下的报错是否是值得我们关注的问题。
值得振奋的是,报错数量大大减少,issue 的数量一下子从 1500+ 降到了 300+。
原来跟劫持有关的噪音数据有这么多吗!(比划了一下大大的手势)
等等!会不会有一些有意义的数据被我们错误地当成噪音过滤掉了?
这么说,其实是有可能的,比如说某个有缺陷的功能在某些地区使用率更高,因此在某些地区的报错占比也更高,但并不是劫持造成的。又或者还有别的原因… 然而,由于我们资源有限,尽管可能损失了一部分有效信息,舍弃这些信息还是可以接受的,总比淹没在浩瀚的无效报错当中要好。
相似 issue 的合并
通过对报错数据的粗略查看,笔者得到了错误信息的一个特征。那就是,由于浏览器不同的缘故,同一个问题会形成不同的报错信息上报到 Sentry。
比如访问了一个不存在的对象的属性"isEdit",会有以下四种报错信息:
1 | TypeError: Cannot read property 'isEdit' of null |
另外,由于百姓网每次部署的时候,都会根据 js 脚本的内容为其生成一个 hash 值作为版本号,每次 js 脚本更新都会产生一个新的版本,引起脚本 url 路径的改变,随之报错也会产生一个新的 issue。
于是同一个问题由于这两种情况会产生出多个 issue。这也意味着,如果我们合并这些相似的 issue,同样可以降低报错的数量。同时还可以消除 issue 的重复问题了。那么怎么合并呢?
要合并相同的 issue,最重要的是如何判断两个 issue 是相似的,也就是应该判断报错信息和报错 js 脚本的路径 URL 是否相同,由于前面所说的,这两者不能做到完全一致,所以可以估算一下它们的相似度,设定一个阈值,来达到目标。
由于现在已经有很多判断字符串相似度的轮子,笔者也没想要造轮子,直接在 NPM 上找了一个可以用的包来用。然而,如果直接比较字符串相似度的话,会遇到一个问题。报错信息中有很多重复出现的词如 undefined, read property, TypeError, function 等等,会增加字符串的相似程度,干扰合并结果。
但是这些重复出现的词,非常典型,枚举出来也并不多,于是笔者打算简单地构建一套正则来移除这些总是出现的词,使用剩下的文本来计算相似度。
这些总是冗余的词句是类似以下这样的:
-
对对象的属性进行操作
- Cannot get property
- Cannot set property
- Cannot read property
- Unable to get property
-
错误类别
- TypeError:
- Error:
- ReferenceError:
- None:
抽取关键词的大致结果:
| 原始信息 | 关键信息 |
|---|---|
| TypeError: Cannot read property ‘isEdit’ of null | isEdit |
| TypeError: Cannot read property ‘call’ of undefined | call |
| TypeError: undefined is not a function | undefined |
从上述结果可以看出,抽取的结果还是勉强可以接受的。于是笔者开始对 issue 进行分类。
首先对所有 issue 进行关键词提取,然后遍历所有 issue 和已经分好的类。如果关键词和某一个类别的关键词相似,则把该 issue 归为这一类,否则新建一个类别,把该 issue 的关键词作为该类别的关键词。
至于报错 js 脚本的 URL 路径的比较,是采用的同样的方式,此处不再赘述。
当我把相似的 issue 合并之后,报错数量再一次减少,issue 的数量从 300+ 降到了 70+。
浏览器偏向性的报错
在过滤劫持相关报错和合并相似的错误之后,笔者还发现一个特征,就是收集到的前端报错除了地区偏向性以外,还有一些具有明显的浏览器偏向性。
例如某个只有 UC 浏览器上报的错误:
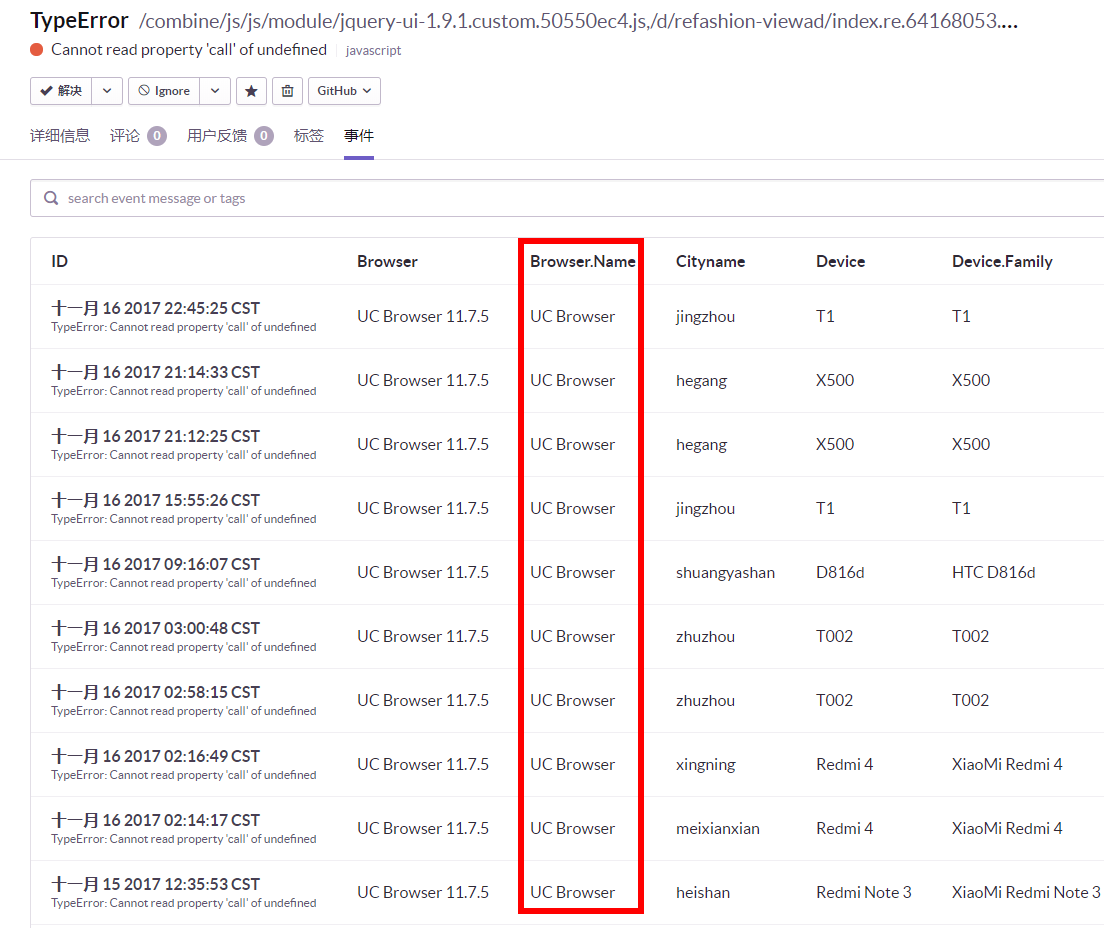
以及搜索引擎爬虫 BingPreview 浏览器上报的错误:
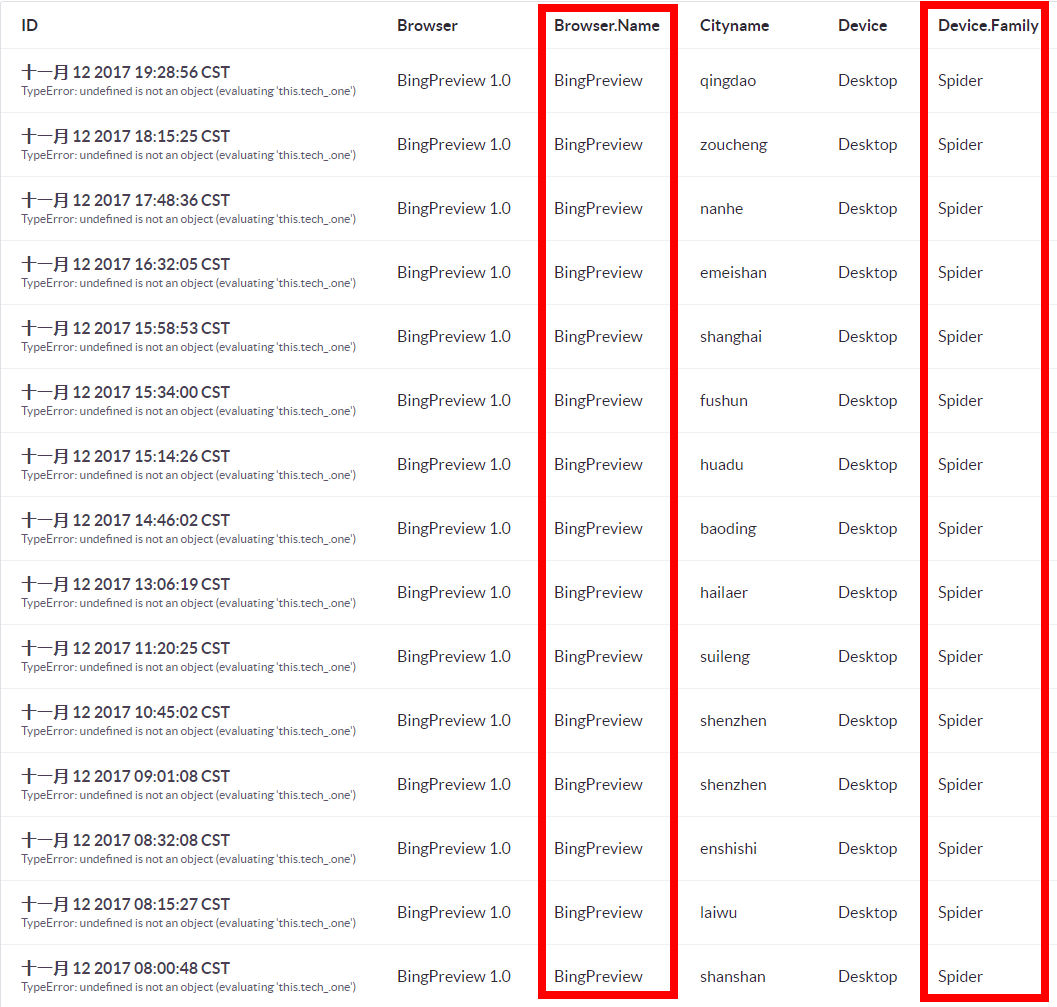
然而通常来说,这种浏览器偏向性的 js 报错,不太能定位到发生的地方,定位出来也是无法理解的问题(摊手
于是把这种错误放到优先级较低的位置,因为通常这种错误不太值得花费人力去修复。
于是,经过细看一些 issue 过后,添加了一个"浏览器黑名单",和过滤"省份黑名单"相似的规则来将这些具有明显浏览器偏向性的 issue 打 Tag 标记。目前被列入浏览器黑名单的有 QQ Browser Mobile、IE、UC Browser。
问题设置优先级
经过前面的处理,报错的数量已经减少到 70+,已经到达了一个可以人工审查的数量级。然而这对于工程师来说,其实负担仍然比较重。
在过滤之后剩下的报错中,还有一些上一个部分说的浏览器相关的错误,其实还有一些是频率比较低的错误(一天不到十次,但一直会有),以及一些报错信息内容太少导致难以定位的错误。这些报错不应该被过滤掉,但是这些报错的存在,仍然可能会把更有价值的错误淹没掉。笔者最后决定把这些报错分类,指定一些优先级来分类。
最终把错误分成了四类:
- 建议关注的错误
- 难以定位的错误
- 低频率的错误
- 浏览器偏向性的错误

其优先级从高到底:

这样,在建议关注这个类别中,只有不到 10 个问题。这对于工程师来说,可能会更加愿意去看这个报错。
小结
经过一系列的数据统计分析,我们发现了前端报错跟地区、浏览器、网络等等因素密切相关,只要找对方法过滤掉噪音,就能从成千上万的报错中要到需要关注的问题。不过,要从根本上解决劫持的问题,还是要早日用上 HTTPS 啊。